
字節跳動日前發布最新的影片生成模型 Seedance 2.0 並且在旗下的即夢、豆包和小雲雀等平台開始內測。官方指 Seedance 2.0 具備導演思維,不單止生成高精度高解像度的單一場面,更能同時生成具備敘事邏輯、連貫的多場景內容,並且配上適當的配音和配樂。不過在令人驚嘆的示範影片之中亦引發了嚴重的隱私與倫理擔憂。官方昨日就暫停了參考真人圖片和影片生成影片的功能,表示會在緊急優化。
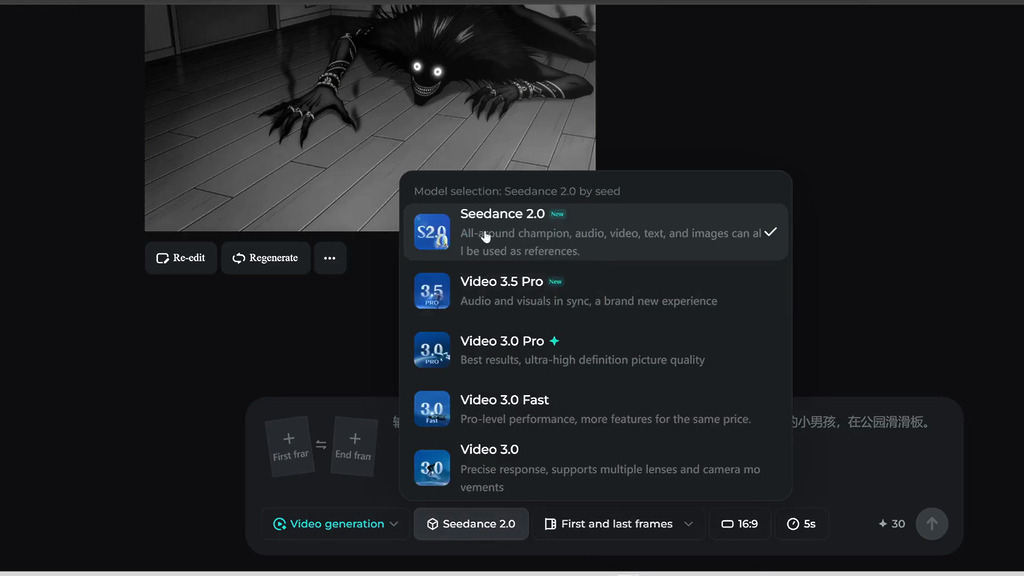
Seedance 2.0 是字節跳動的最新多模態影片生成模型,它採用雙分支擴散 Transformer 架構,能同時生成視頻畫面與原生音頻。用戶只要輸入文字提示句或上傳圖像,模型即能自動設計敘事邏輯和分鏡,在 60 秒內生成連貫的高解像度多鏡頭影片,並且能保持角色形象的一致性。
Seedance 2.0 最多可參考 9 張圖片、3 段影片和 3 段音頻,最高輸出解像度可達 2K,但要生成專業電影級影片則以 720p-1080p 解像度為主。影片長度最長可達 30 秒。
侵權、私隱惹憂慮
不過在觀賞令人驚嘆的影片的背後,亦引來不少製作人對今後人工智能生成影片能力的擔憂。國內視頻媒體 Mediastorm 影視颶風創辦人潘天鴻就發現他只要上傳一張自己的臉部照片,Seedance 2.0 就能生成幾乎與他本人一致的配音影片。他對 Seedance 2.0 不需要聲音樣本就能生成該人語音的能力感到可怕。
他認為字節跳動可能在訓練模型時,參考了很多網上視頻而未得視頻製作人的同意。他認為過去他花了上百小時製作的影片,Seedance 2.0 幾十秒就能產生高質量的影片,他擔心到下一代模型將會完全改變電影業,質疑這對人類來說是好是壞。
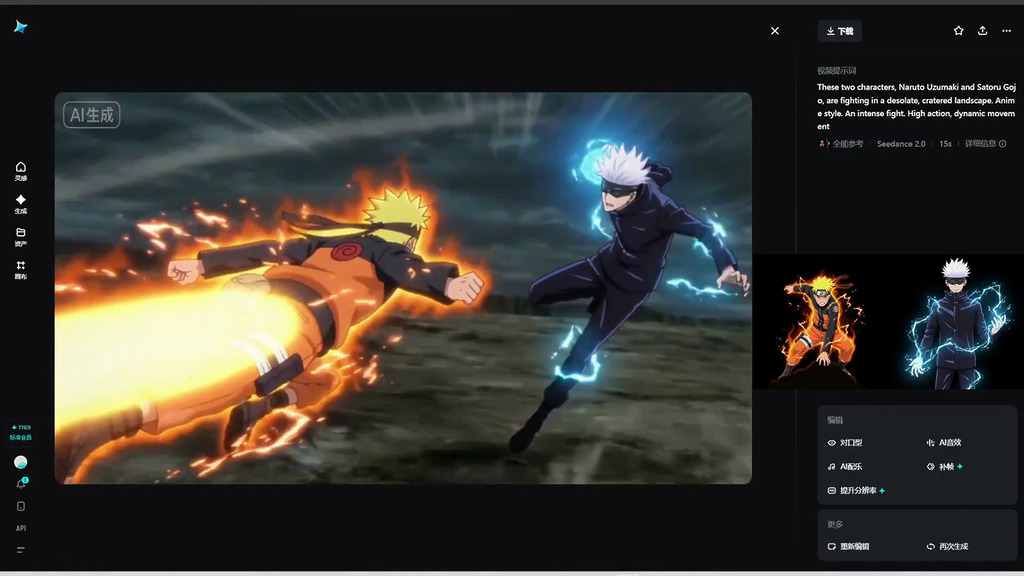
其他製作人測試過 Seedance 2.0 後,亦對它單憑一張版權角色圖片就能生成該角色的影片感到擔憂,恐怕今後會有更多 IP 被人肆意生成內容。
針對侵權爭議,即夢方面已經暫停了 Seedance 2.0 參考真人圖片和影片來生成影片的功能,即夢方面表示:「為了維護健康、可持續的創作環境,我們正在緊急更新模型,並立即暫停使用真實照片或視頻作為參考主體的功能。」而豆包應用亦增加了活體驗證步驟,要求用戶在創建數碼化身前需錄製自己的影像與聲音。字節跳動強調,這些調整旨在堅守責任底線,同時平衡創新與監管合規。
