
隨著人工智慧正式邁入「智能代理(AI Agent)」時代,Google 在最新的基礎設施大會上正式發表了第八代自研 AI 晶片——TPU 8t 與 TPU 8i。這對「雙子星」晶片的出現,標誌著 Google 首次將 AI 運算架構明確劃分為「訓練(Training)」與「推理(Inference)」兩大專屬領域,旨在解決未來 AI 代理在複雜推理時的延遲痛點。
訓練與推理「分家」:專機專用效率更高
過去的 TPU 往往追求全方位的性能提升,但來到第八代,Google 選擇了精細化運算路線。
• TPU 8t (Training): 針對大規模模型預訓練設計。透過 3D Torus 網絡拓撲,單個 Pod 可串聯多達 9,600 個晶片,總算力達到驚人的 121 ExaFlops。官方數據顯示,其每美元訓練性能比前代提升了 2.7 倍,更具備高達 97% 的「有效算力」穩定度,確保數月不間斷的訓練任務不會因故障中斷。
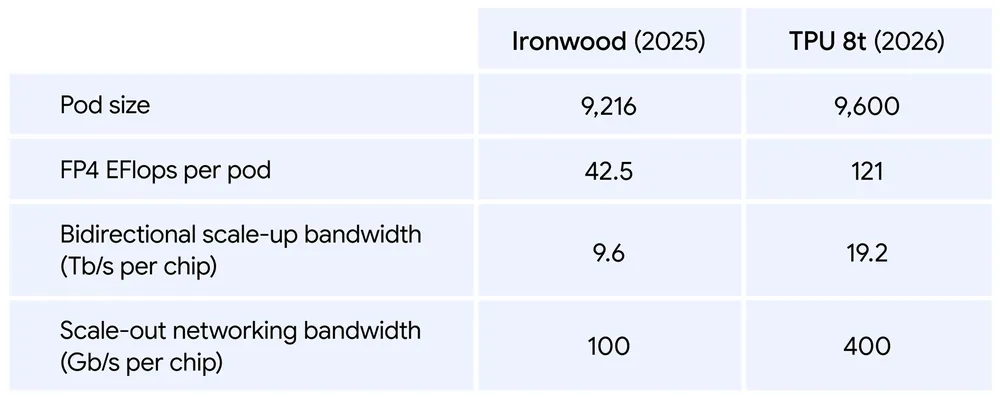
• TPU 8i (Inference): 則是專門為「AI 代理」量身打造的推理晶片。面對需要多步驟、長鏈條邏輯思考的任務,TPU 8i 配備了比前代多 3 倍的 SRAM 記憶體,能有效加速大規模語言模型(LLM)的生成速度,並支援多個 AI 代理協同作業的「蜂群(Swarming)」運作模式。

能源效率翻倍 解決 AI「候診室效應」
Google 指出,傳統硬件在處理多個 AI 代理協作時,常會因為處理器間的溝通延遲產生「候診室效應(Waiting Room Effect)」。TPU 8i 透過優化的內存帶寬和傳輸路徑,大幅降低了推理延遲。更重要的是,在追求效能的同時,兩款新晶片的每瓦性能(Performance-per-watt)均比上代提升了 2 倍,對於急需節能減碳的數據中心而言,無疑是一大福音。
配套升級:打造完整 AI 生態圈
除了硬體晶片,Google 同場亦加映了多項底層配套,包括速度提升 20 倍的 Hyperdisk ML 存儲方案,以及專為超大型數據交換設計的 Virgo 網絡架構。
Google 這次將 TPU 拆分為訓練與推理兩條路線,反映出業界對 AI 發展的看法已從「堆砌算力」轉向「優化成本與體驗」。對於開發者而言,這意味著未來運行複雜的 Agent 應用時,能以更低的預算換取更流暢的反應速度。隨着 TPU v8 投入服務,Google 在雲端 AI 市場的競爭力將再次與 NVIDIA 形成正面交鋒。
